
Google BigQueryとは
概要
Google Cloud Platform(GCP)で提供されているるエンタープライズ向けのデータウェアハウス。BigQueryの最大の特徴は「高速なデータ処理」。一般的なRDBMSでは行単位でデータが保存されるが、BigQueryでは列単位でデータが保存される。
また、フルマネージドサービスなので、インフラの保守・運用はBigQuery側がやってくれるため、本来やりたいこと(データ収集、分析)に集中できる
SQLを書ければBigQueryもサクッとかけるはず。
BigQueryの扱うテーブル
BigQueryは次の3つのテーブルタイプがある
- ネイティブテーブル:BigQuery ストレージに格納されるテーブル
- 外部テーブル:BigQuery の外部にあるストレージ(Google Cloud Storage や Google ドライブ等)でサポートするテーブル
- ビュー:SQL クエリによって定義される仮想テーブル
BigQueryの動作確認
※本記事ではプロジェクトは既に作成・選択済みの前提で手順を進める。未作成の方はこちらの記事のプロジェクト作成の部分を参考にされたし
Google App Engineのフレキシブル環境にpythonアプリケーションをデプロイする方法
一般公開データセットに対してクエリ上を実行
こちらの公式ドキュメントのクイックスタートの内容を元に進める
https://cloud.google.com/bigquery/docs/quickstarts/query-public-dataset-console?hl=ja
既にBigQuery側で一般公開データセットが用意されているので、そちらに対してクエリを実行する
こちらのurlにアクセスすると、GCPのbigqueryのSQLワークスペースが表示されるので、このクエリを開くのボタンを押す
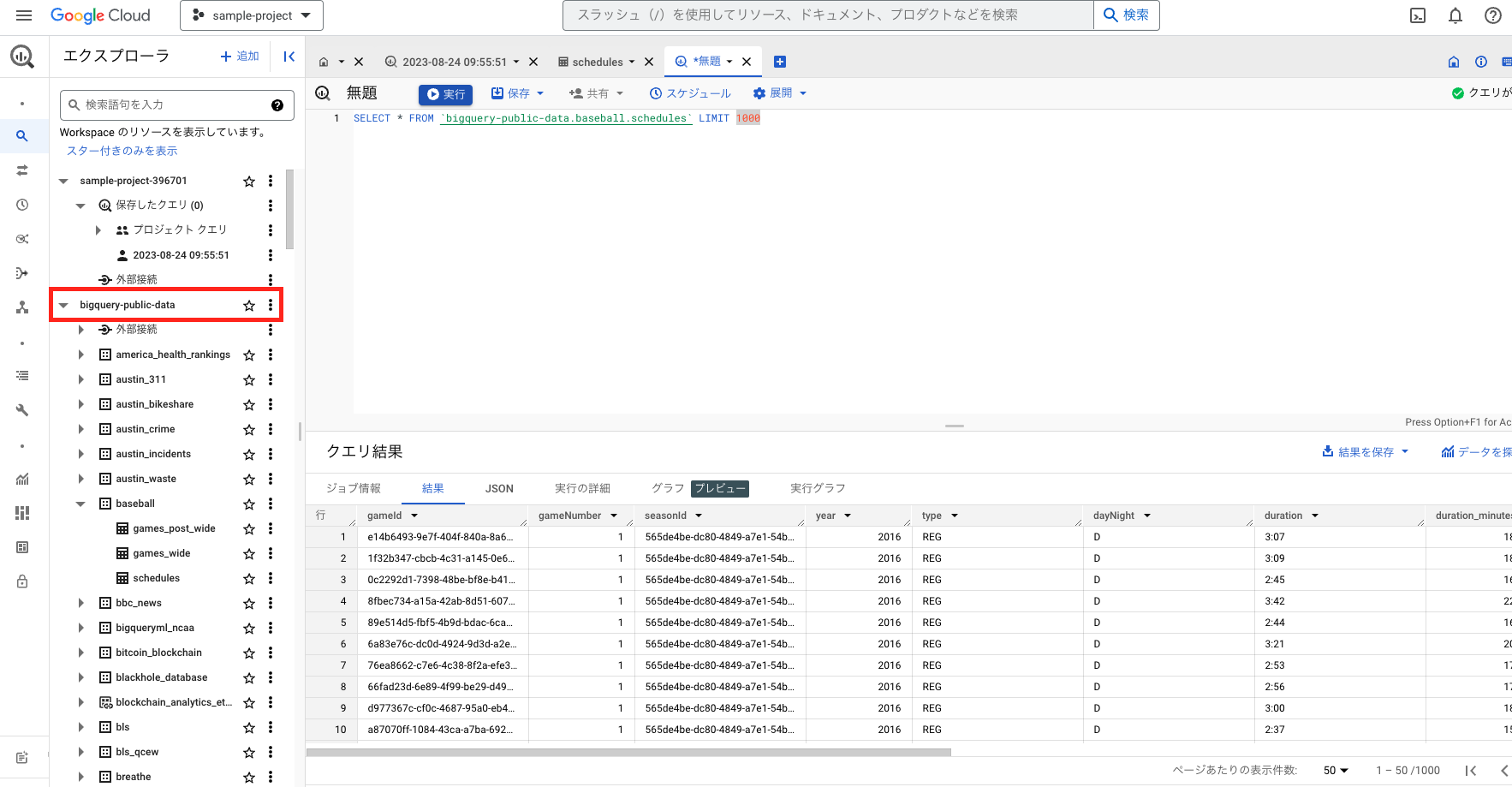
bigquery-public-dataに色々なサンプルデータがあるので、こちらから任意のテーブルを選びクエリを実行することが可能
BigQueryでCloud Storageのデータをクエリする
cloud storageでバケットを作成
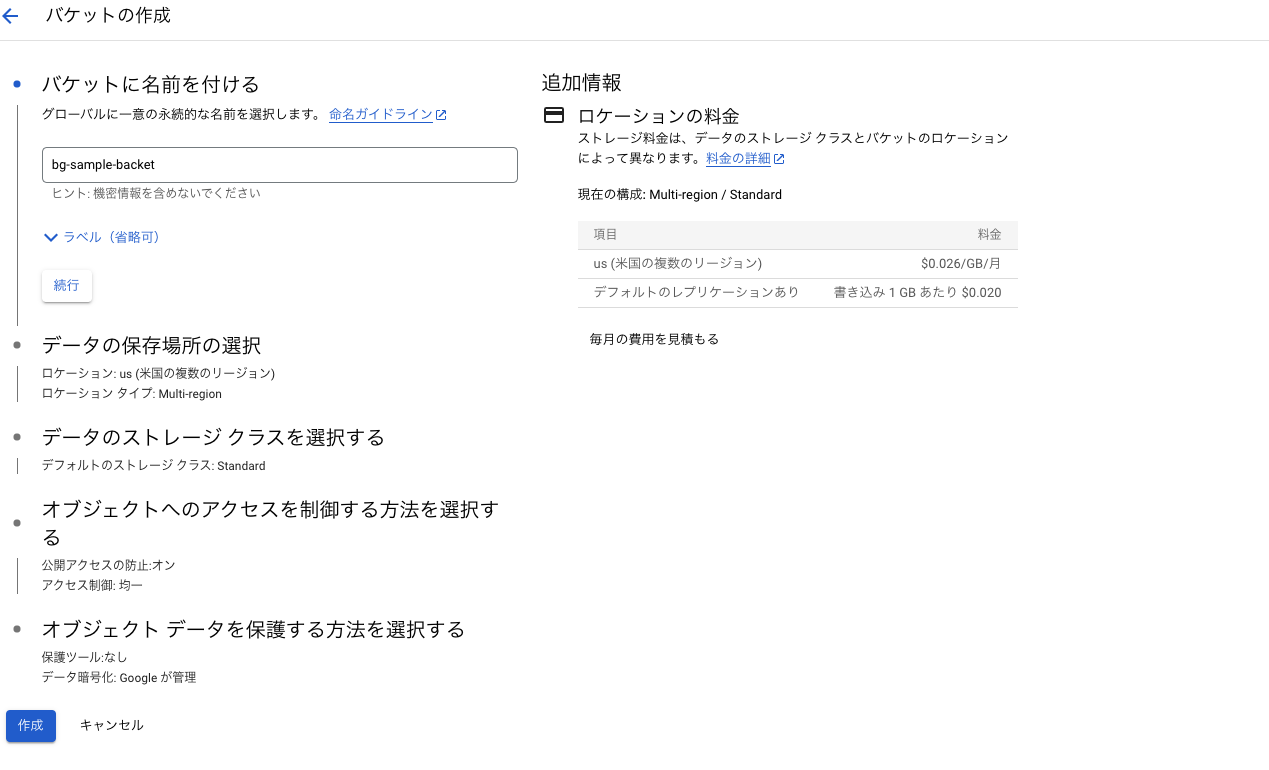
任意の名称をつけ、作成を押す
cloud storageにcsvをimportする
ファイルをアップロードを選択
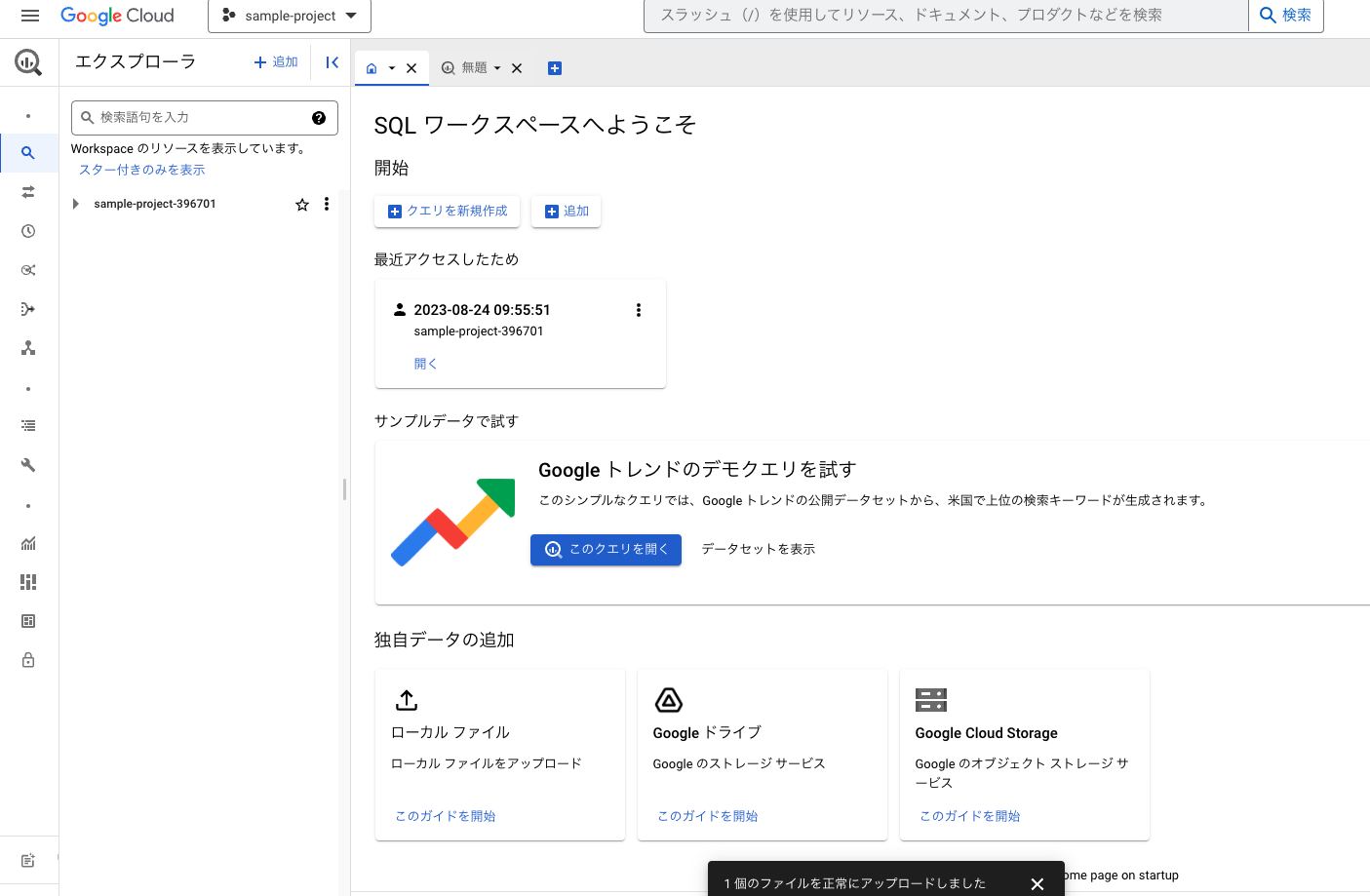
BigQueryに戻り、左上の追加をクリック
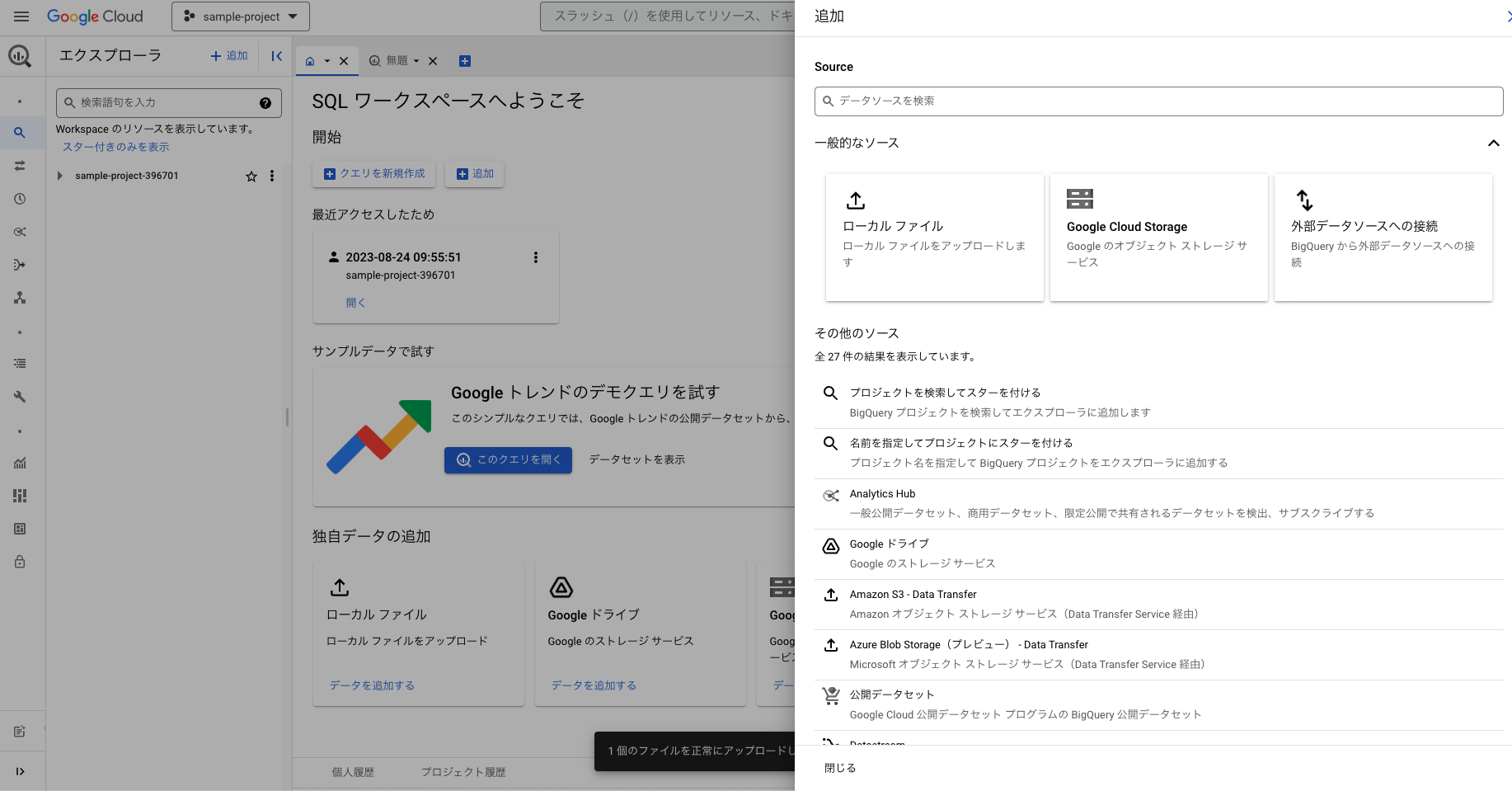
ローカルファイル、外部データソースの間にあるGoogle Cloud Storageを選択
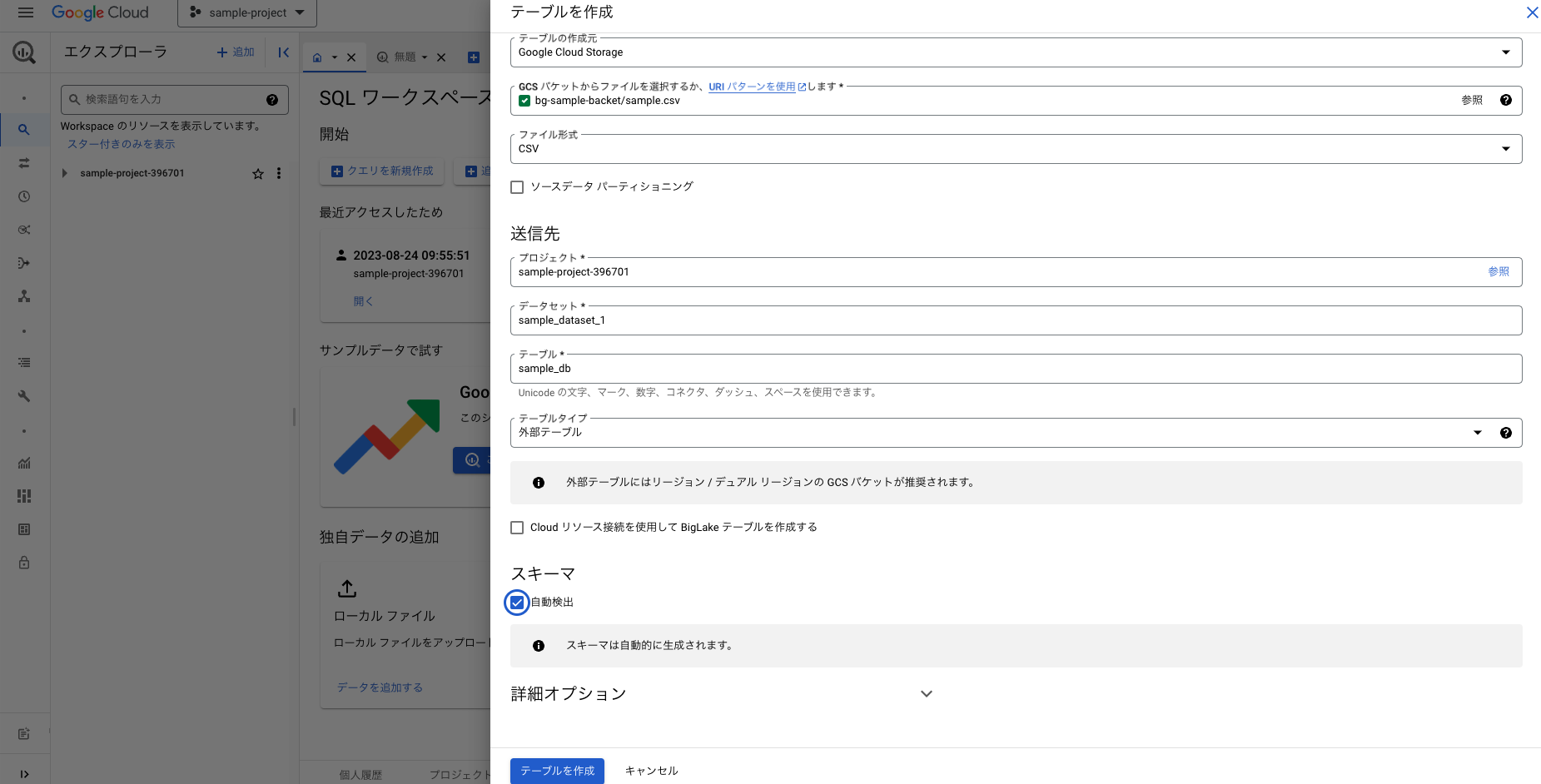
テーブル名など入力できたらテーブルを作成をクリック。なお、テーブルの種類は外部テーブルを選択すること
新しくdbが追加される。
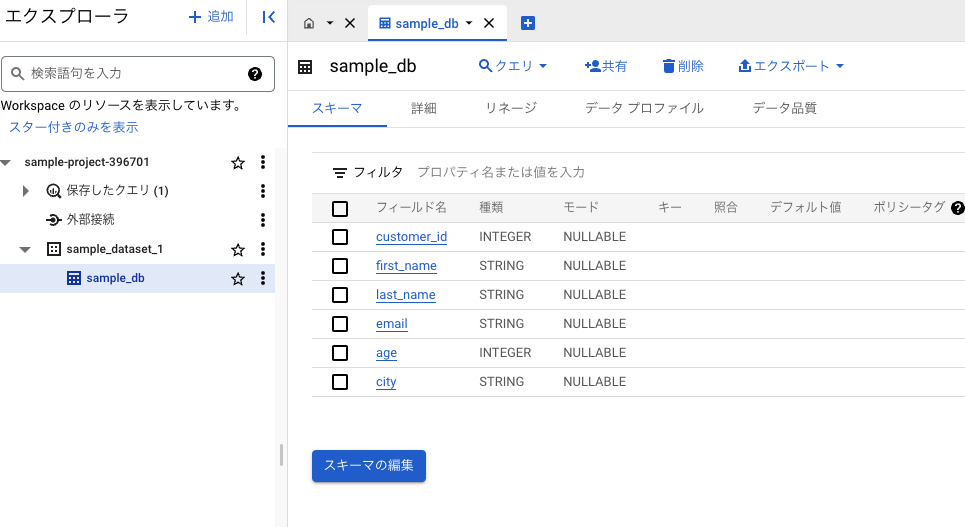
Google Cloudからクエリを実行
新しくクエリを作成し、sqlを実行するとdbからデータを取得できているのがわかる
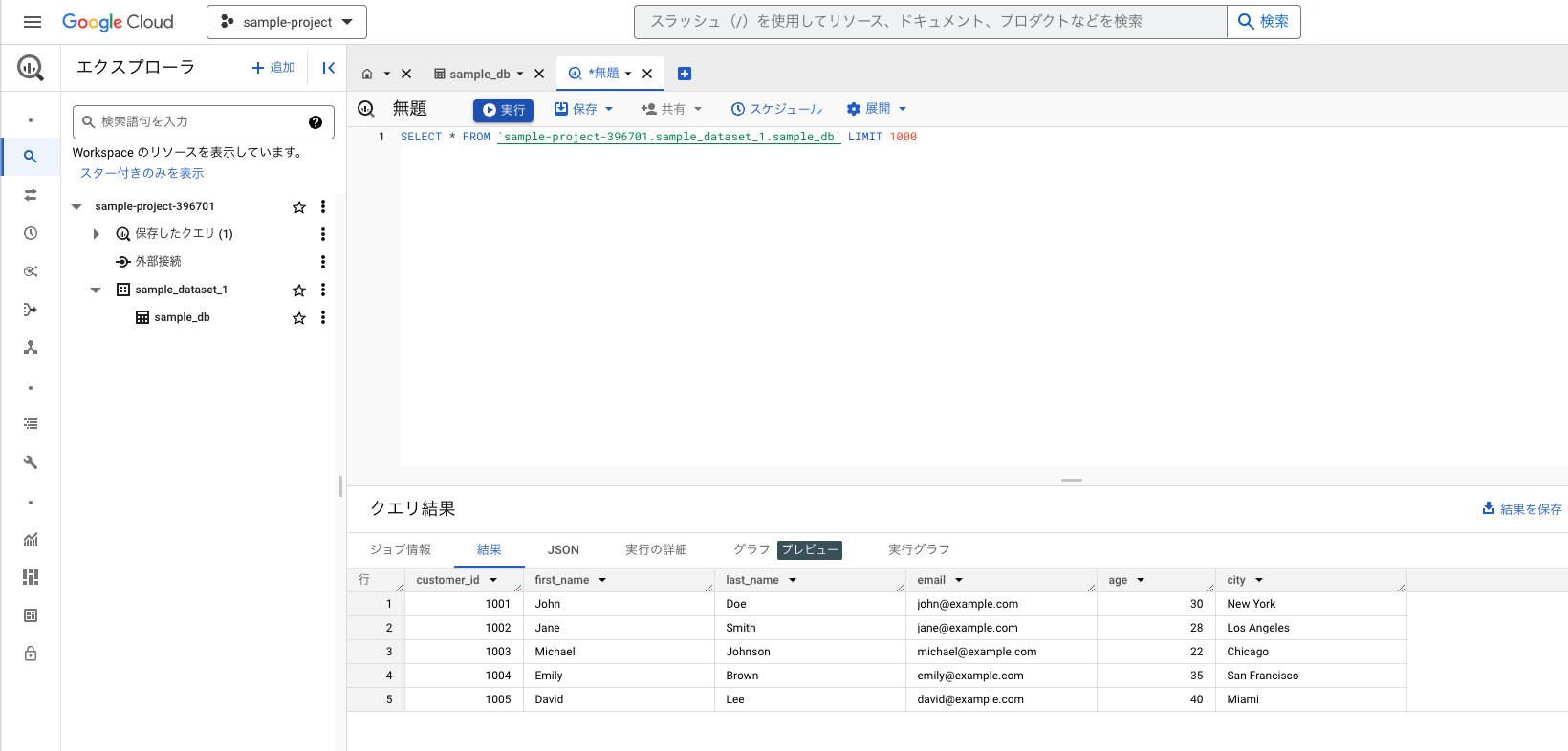
プログラムからクエリを実行
pythonからBigQuery APIを叩くことでクエリを実行する
BigQuery API の Cloud クライアント ライブラリをインストール
pip install google-cloud-bigqueryAPI へのアクセスの有効化からAPI アクセスを有効化

Google Cloud のホームページの手順にしたがい、サービスアカウントを作成
サイドバーからサービスアカウントの一覧
サービスアカウントを作成をクリック
サービスアカウント名などを入力し、完了をクリック
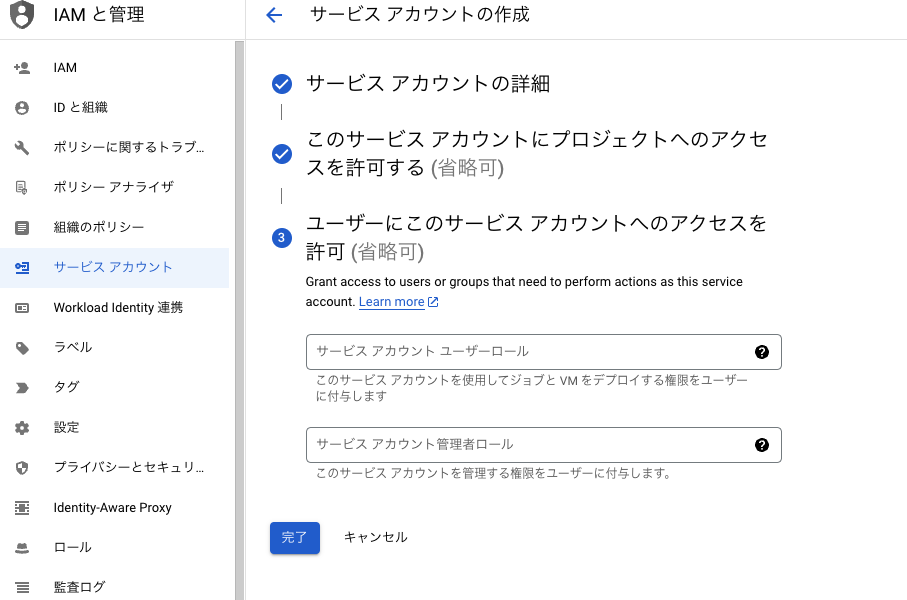
Google Cloud のホームページの手順にしたがい、サービスアカウントキーを作成して service-account-key-file.json をダウンロード。この json ファイルを GCP の認証に使用する
対象のサービスアカウントのメールアドレスの箇所をクリック
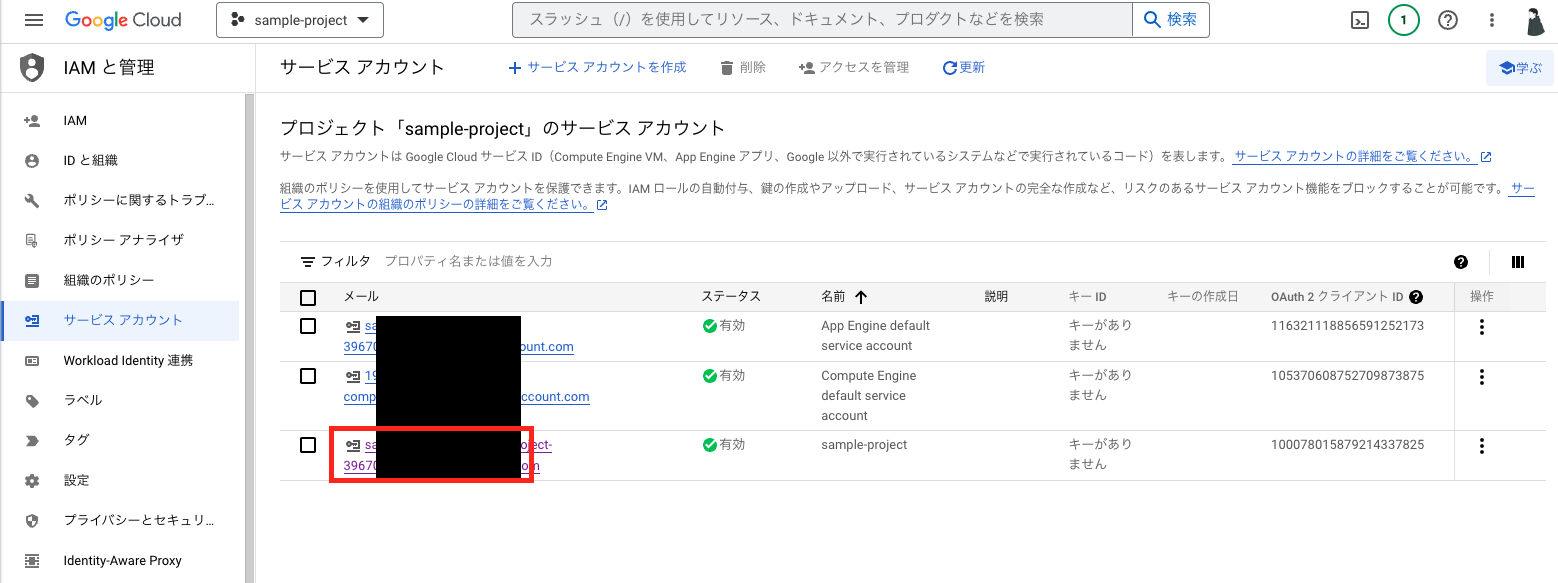
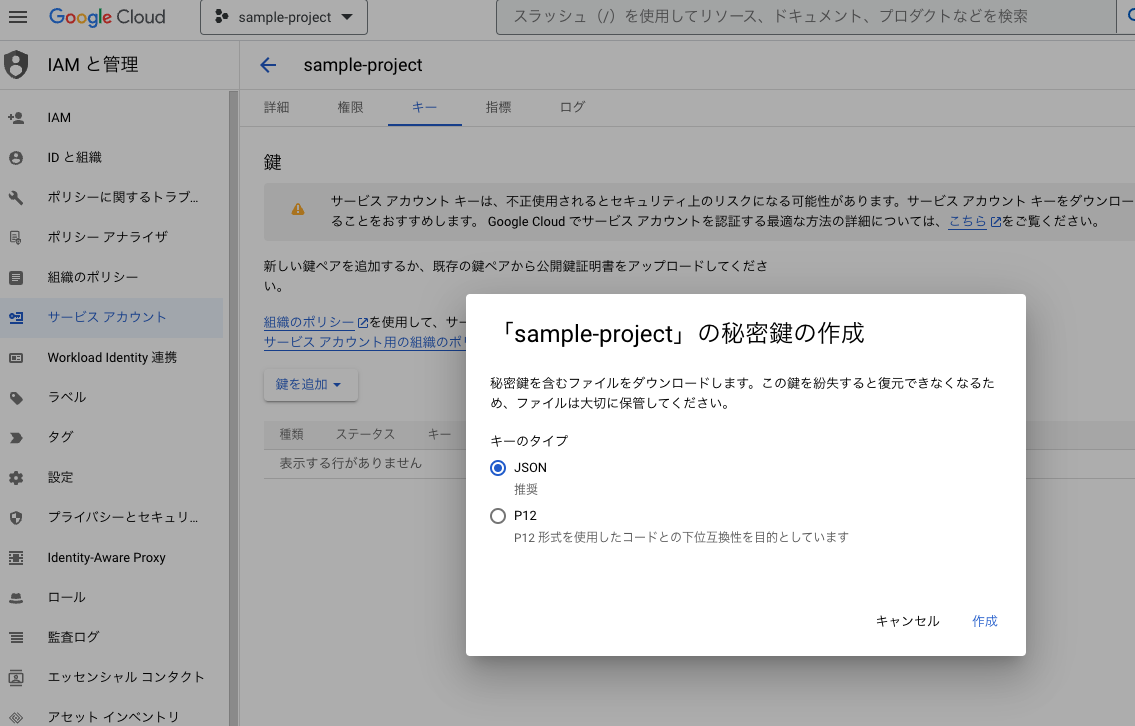
キータブをクリックし、
新しい鍵を作成を選択(タイプはjson
まとめ
いかがでしたでしょうか。本記事では、Google BigQueryでGoogle Cloud Storageのデータをクエリする方法について紹介しました。同じようなアーキテクチャを構築する際は、ぜひ参考にしてみて下さい。



