
Cloud Monitoringとは
Google Cloud上で作成したリソースを監視するサービス。これを使用すると、収集した指標が事前に設定した条件を満たした場合に通知するといったことが可能になる
Cloud Monitoringの料金体系
従量課金制。クレジット(請求先アカウントごとに最初の 150 MiBが毎月の無料割り当て)がある
実装手順
Memorystore for Redisのシステムメモリ使用率が80%を超えた場合に、指定のメールアドレスにアラートを送信するという例で作成する
通知先の登録
Google Cloud Monitoringのアラートから、画面上部のEDIT NOTIFICATION CHANNELSをクリック
Emailの項目を見つけ、メールアドレスや表示名などを設定し登録する

アラートポリシーの作成
アラートポリシーは、通知を行うための条件。Google Cloud Monitoringのアラートから、画面上部のCREATE POLICYをクリック
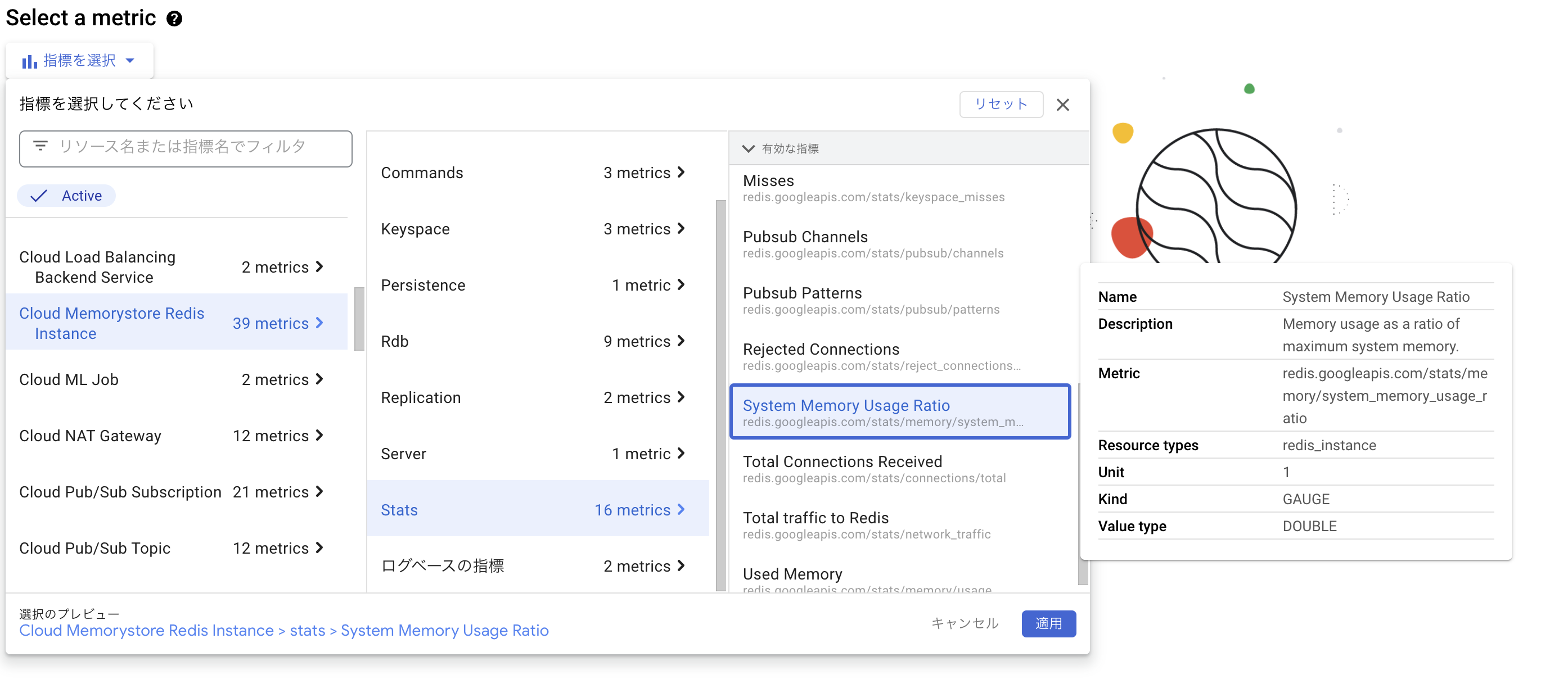
アラートポリシーは、各リソース毎にCPU使用率、ログベースなど様々な指標に基づいて作成することが可能。今回はRedisのシステムメモリ使用率(Cloud Memorystore Redis Instance > stats > System Memory Usage Ratio)を指定
画面上に表示されている設定項目は以下の通り
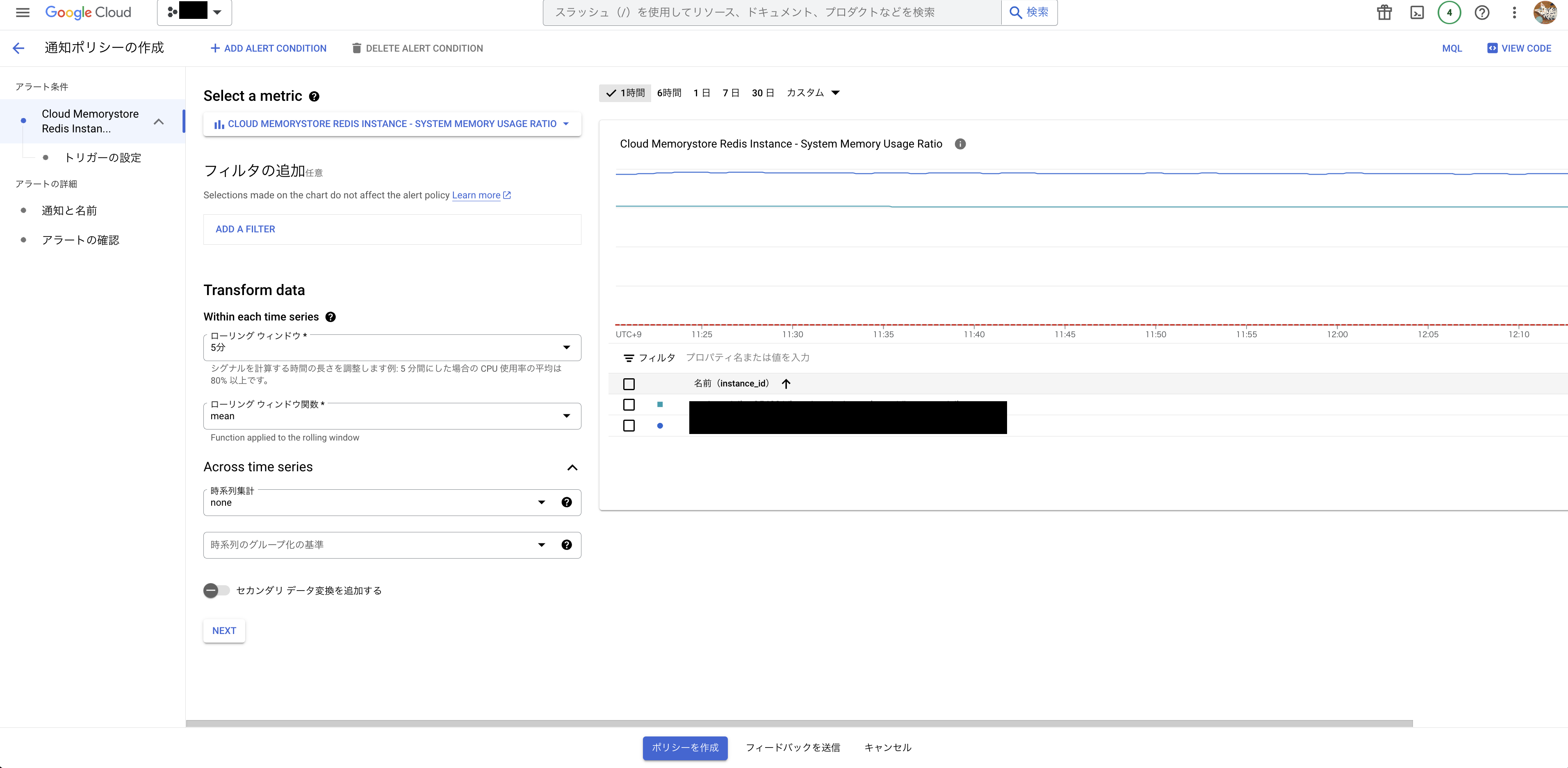
フィルタ
フィルタでは、例えば環境によってRedisインスタンスをdevelopとstagingで分けている場合に、それぞれの環境毎のインスタンスを指定する等の条件指定が可能になる項目。つまり監視対象のリソースを絞り込むことが可能
Transform data
- ローリング ウィンドウ(リソースの監視間隔)
例えば1分を指定すれば過去1分間のデータを取得して異常を検知するようになる - ローリング ウィンドウ関数(リソースの監視間隔中の指標データに適用される処理)
max(最大値)、min(最小値)、mean(平均値)などが設定できる
今回は1分間隔で監視し、システムメモリ使用率の最大値をもとにアラートを送信したいので以下のように登録
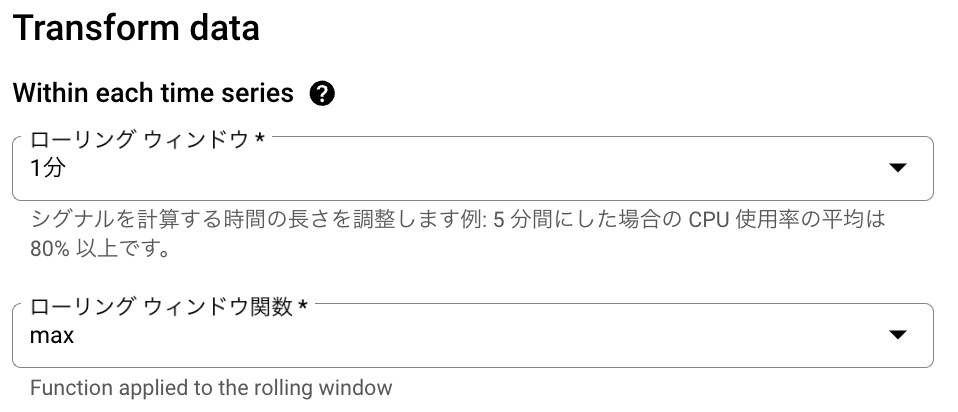
- Across time series
異なるリソース、サービス、またはメトリクスから収集されたデータを統合し、新しい情報を生成するために使用される。今回は不要なので特に指定しない。NEXTをクリック
トリガーの設定
- Condition type(監視条件の種類)
- Threshold(しきい値条件)
監視間隔中にしきい値を上回った(下回った)ことをアラートをトリガーとして設定したい場合に使用する
- Metric absence(不在条件)
監視間隔中に特定のメトリクスデータが無いことをアラートトリガーをして設定したい場合に使用する。ポリシーの設定以降にメトリクスのデータの取得が1回以上成功している必要がある
- Threshold(しきい値条件)
- Advanced Options
このオプションを特に指定しない場合、アラートがトリガーされた瞬間にアクションが実行される。再テストウインドウを設定すると、指定した時間経過後にアラートをテストし、そのタイミングにおいても指標に合致する(=問題が持続している)と判定された場合において初めてアクションが実行されるようになる。これは、一時的なスパイクや誤検出の回避に役立つオプション
- 条件名
アラート条件に任意の名前を設定可能
今回は条件をThresholdで任意の時系列の違反、しきい値より上、しきい値を0.9で設定
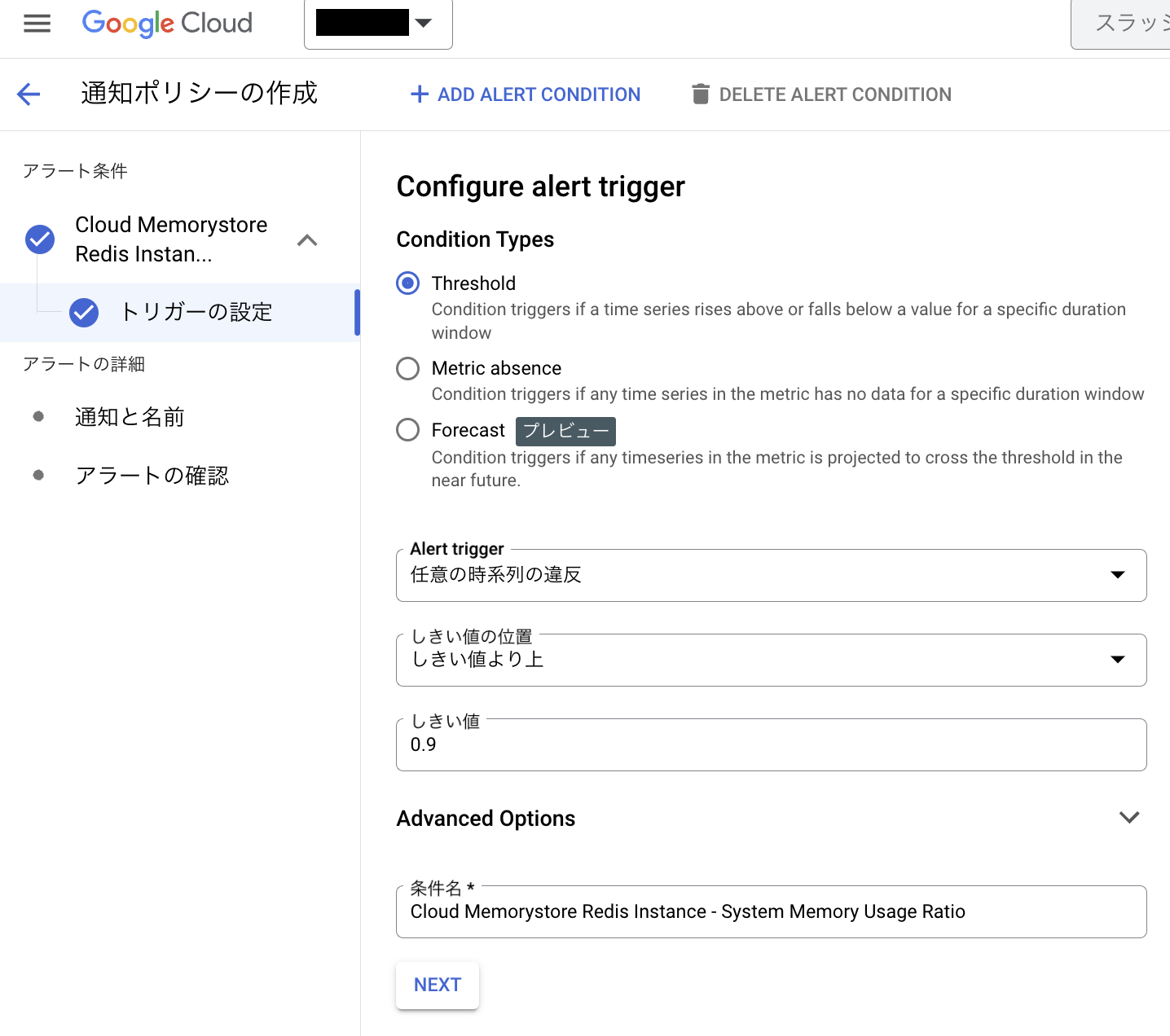
NEXTをクリック
アラート通知設定
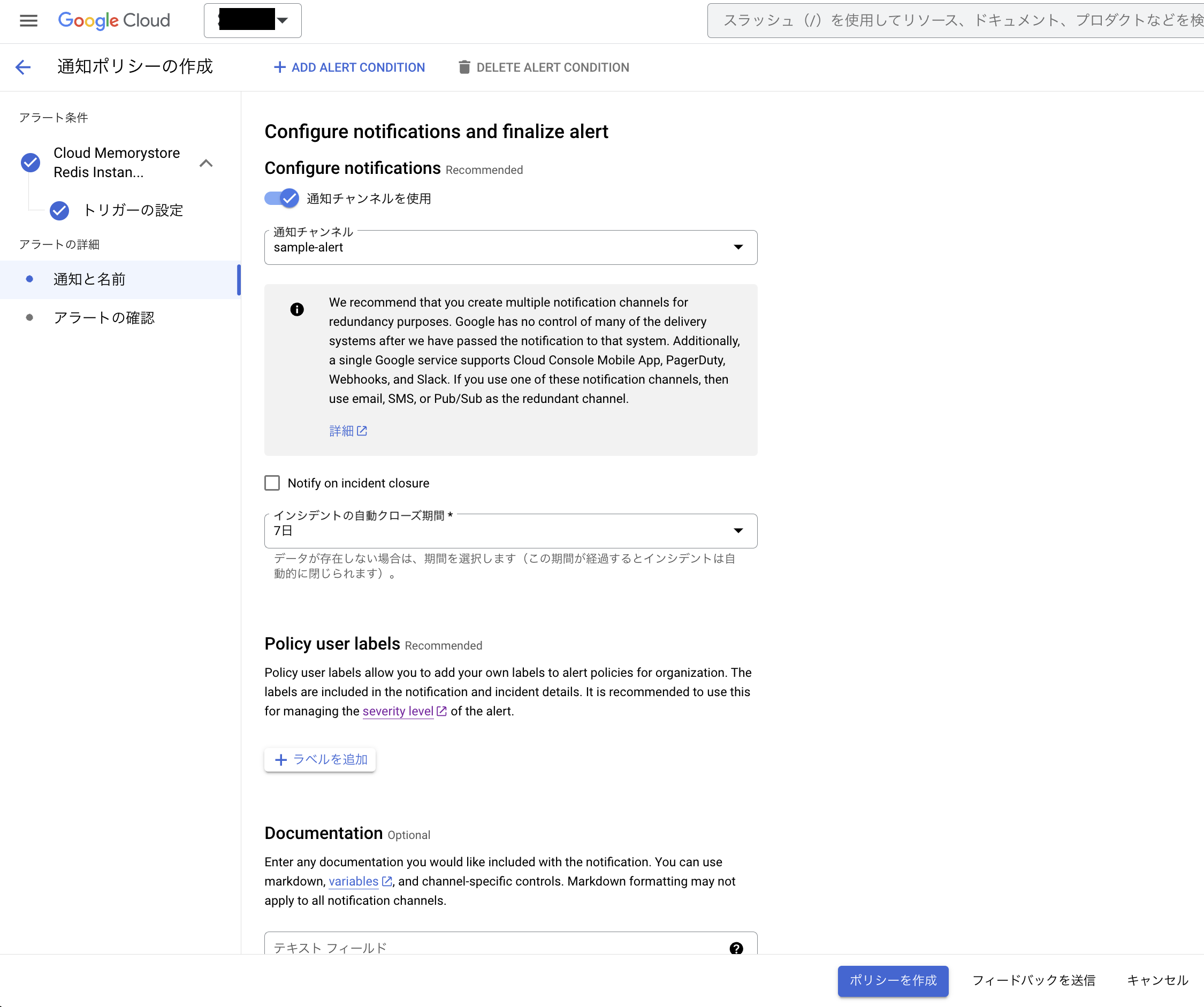
- Configure notifications(通知設定)
通知チャンネルを使用にチェックをつけると、事前に登録された通知チャンネルにアラートを送信することが可能
- Notify on incident closure(インシデントクローズ時の通知)
Cloud Monitoringでは、アラートがトリガーされると自動でインシデントをオープンし、基準値の範囲内に戻ったらクローズする機能があり、この項目にチェックをつけると、インシデントがクローズした際にも通知するようになる
- インシデントの自動クローズ期間
Cloud Monitoringが自動でインシデントをクローズする期間を設定する
- Notify on incident closure(インシデントクローズ時の通知)
- Policy user labels
アラートに任意のラベルを付けることが可能。例えばアラートポリシーに重大度レベル(serverity)を追加することが可能
- Documentation
テキストやマークダウンを使用してアラート内容のテキストを追加することが可能
- Name the alert policy(アラートポリシーの名前)
NEXTをクリックして確認画面で内容を確認し問題なければポリシーを作成ボタンをクリックすると、アラートポリシーが作成される
アラートの動作検証
検証のため、一時的にアラートのトリガーのしきい値を0.001に変更する
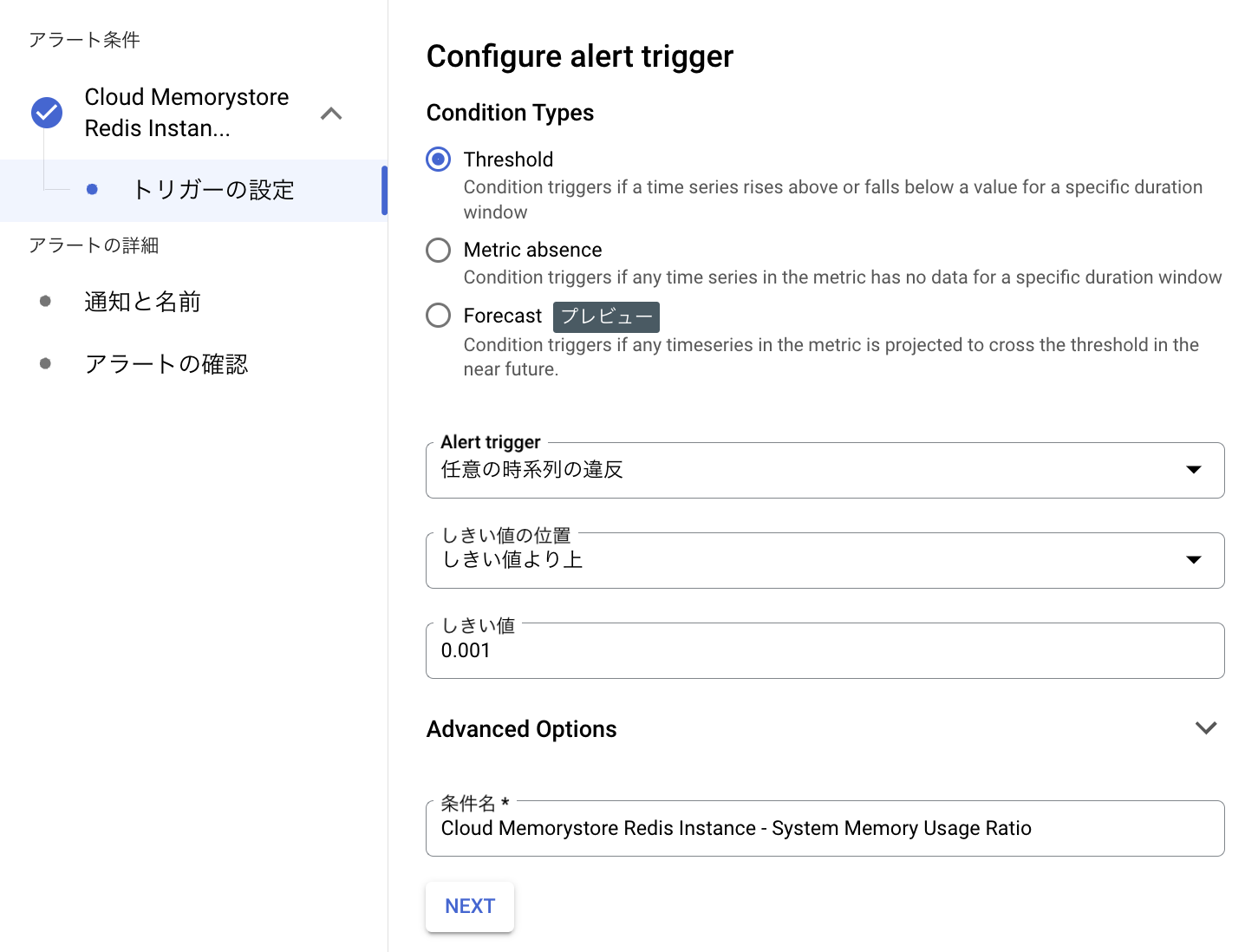
これで、ローリングウインドウで指定した時間内にメールにアラートが届いていれば成功
通知の仕組み
Cloud Monitroingはアラートポリシーの条件が満たされるとGoogle Cloud Consoleにインシデントを作成して表示するようになっている

インシデントには「オープン」、「確認済み」、「クローズ」の3種類がある。
インシデントが生成された直後は「オープン」となり、アラートダッシュボードから該当するインシデントを選択し確認を押すことで「確認済み」となる。
そして、
- ポリシー作成時に設定したクローズ期間を経過してもアラートがトリガーされなかった場合
- メトリクスがアラートポリシーの条件を満たさなった場合
にインシデントがクローズされる。
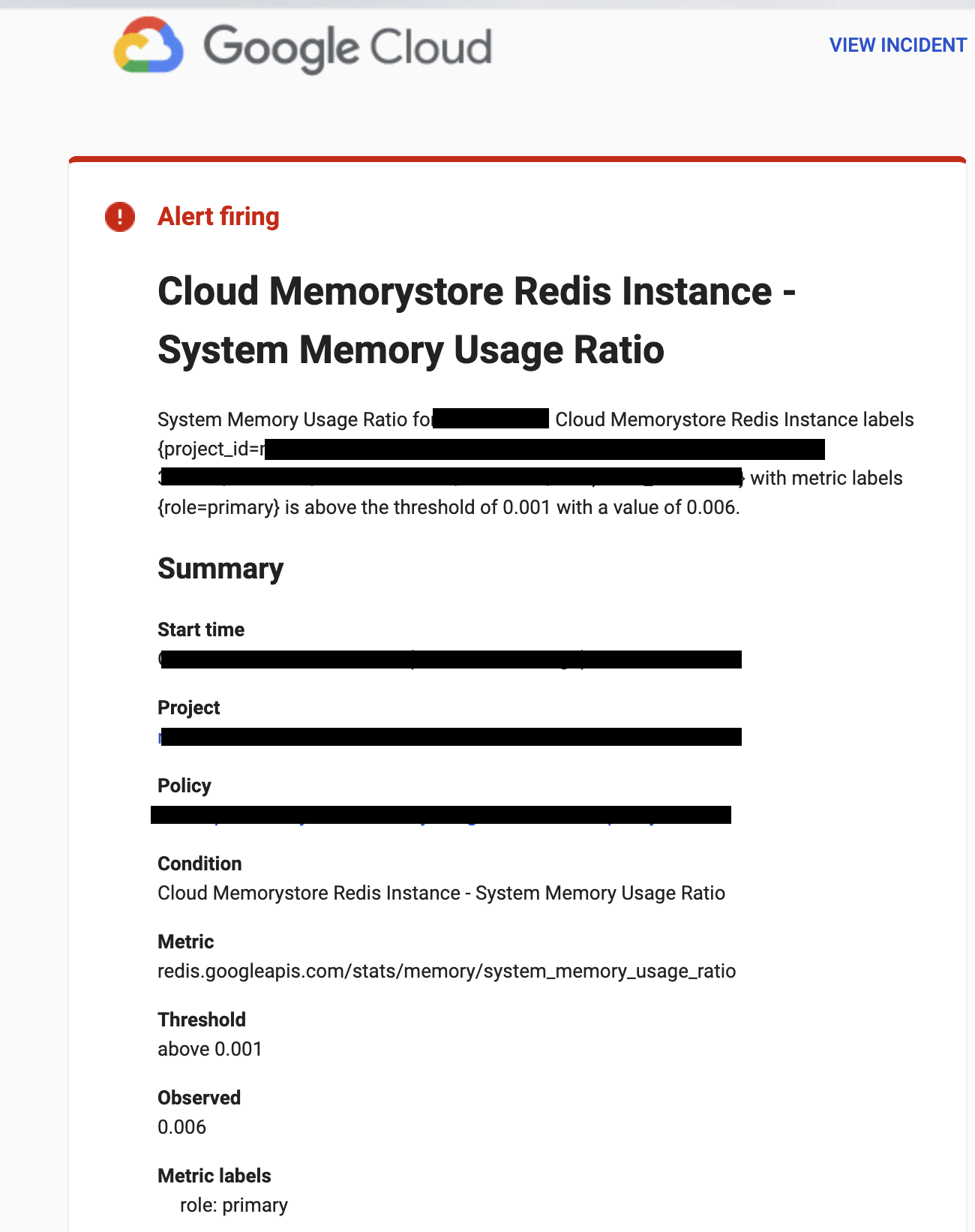
Notify on incident closure(インシデントクローズ時の通知)の通知
アラート作成時にこれを有効化していた場合、下図のような通知が来る。

ログベースのアラート
すでに紹介したアラートは、メトリクスベースのものになるが、ログベースのアラートも作成することが可能(例えばGoogle AppEngineのステータスコードが500のレスポンスログ)。Cloud loggingからログクエリで該当のクエリを絞り込み、アラートを作成をクリックするとサイドバーが展開され、アラートポリシー名や通知先、条件などを指定して作成できる。
まとめ
いかがでしたでしょうか。本記事ではGoogle Cloud Monitoringを使用してサービス監視の仕組みを構築する方法について紹介しました。ぜひ参考にしてみてください


